

Robust Predictions And Increased Interpretability Through Domain-Directed Modeling
Published August 24, 2022

Rob Zinkov
Co-Authors: Brian Skinn, Eric Kelly
Every tech era has buzzwords and trends that are billed as worthy of saving the world or positioned as if they'll one day take it over. In the 1990s we had the “information superhighway,” the 2000s gave us “web services,” and in the 2010s “Big Data” and “machine learning” were everywhere.

Monthly phrase counts retrieved from Google Books Ngram Exports
Machine learning is one field that has proved to be far more than a passing fad, however. Instead, it has grown into an established academic discipline with significant value and staying power, and is often the first tool that data analysis folks reach for to solve their problems. To be sure, machine learning has significant strengths, especially when large amounts of clean, consistent data are available, and it’s providing dramatic benefits across fields as diverse as medical imaging, product recommendation, language translation, self-driving cars, and traffic analysis.
There are numerous areas where machine learning is not necessarily the optimal tool, though, especially where data is lacking or of poor quality, or where visibility into the model’s internal decision-making processes is critical. In these situations, modeling techniques that make use of the processes underlying the data, informed by domain-specific expertise, are often able to outperform machine learning methods. Such ‘domain-directed’ methods are a great addition to your toolbox—they can be effective when machine learning fails or reaches its limits, and they often provide superior predictive performance in addition to improved model interpretability.
Defining “Algorithmic” vs “Domain-Directed” Modeling Approaches
A little over two decades ago, Leo Breiman published Statistical Modeling: The Two Cultures, where he outlined two ways statisticians go about modeling data. One approach seeks, with the help of domain expertise, to explicitly model the processes by which the observed data was generated, while the second approach focuses on prediction and forecasting based on algorithmic processing of just the available data itself, without reference to an underlying model. Stated another way, these contrasting approaches explore a fundamental question: Do we care about understanding, or is simply predicting future data good enough?
The latter approach, called algorithmic modeling by Breiman, has become the dominant paradigm used everywhere from classical domains like time-series forecasting to modern machine learning methods. But with recent advances in both deterministic statistical libraries such as scipy.stats, Pingouin, and statsmodels, and also probabilistic programming libraries including Stan, PyMC, Bean Machine, and NumPyro, we are seeing a revival in the more classic domain-directed approach, albeit with advanced, modern tools. Deterministic tools represent one class of domain-directed methods, which treat input data as a set of discrete values and carry out statistical analysis and modeling of that input data. Probabilistic programming libraries are another type of domain-directed analysis tools that explore the full distribution of possible inputs and outputs for a system of interest. In particular, probabilistic programming tools are able to treat input parameters as complete statistical distributions, rather than just discrete values.
Quansight has significant experience with these libraries, and also contributes regularly to SciPy, Bean Machine, and PyMC. We are therefore able to apply them readily to our clients’ projects where appropriate. In this post, we’ll show some of the advantages of domain-directed approaches, to help you decide if they’re right for your problem.
Exploring Domain-Directed Approaches
So, first of all, what’s the appeal of domain-directed approaches?
One good way to illustrate the appeal is with a story from the history of astronomy. For many centuries, we predicted the paths of planetary motions using recorded tables of distances of the planets from the Earth. These predictions were based on geocentric assumptions that planets orbit around the Earth, and had noticeable errors. Attempts to resolve these errors spurred the development of the theory of epicycles, where planets are assumed to have invisible orbits within orbits. These epicycles had lower prediction error but were very cumbersome to compute, especially in the era before computers. They also relied on a physical model that we know today—and that, despite apocryphal accounts, they also knew at the time—to be false.
Eventually, starting with the work of Copernicus and ultimately culminating with the work of Kepler and Newton, we moved to heliocentric models of planets in elliptical orbits around the Sun. This greater understanding led to models that were not just more physically sensible, but that were also simpler and provided more accurate predictions.
The figure below illustrates how a more-complex, less-realistic epicycle model can be made to match the observed distance over time between two planets in elliptical heliocentric orbits approximating those of Earth and Mars. In the epicycle model on the left, Earth (blue) is stationary and Mars (red) orbits in a circle that itself is orbiting the Earth. In the heliocentric model, both planets are orbiting the Sun (yellow). The center panel plots the Earth-Mars distance for both the epicycle (dashed line) and heliocentric (solid line) models, showing how the epicycle model provides a reasonable but inexact match to the more physically realistic heliocentric model.
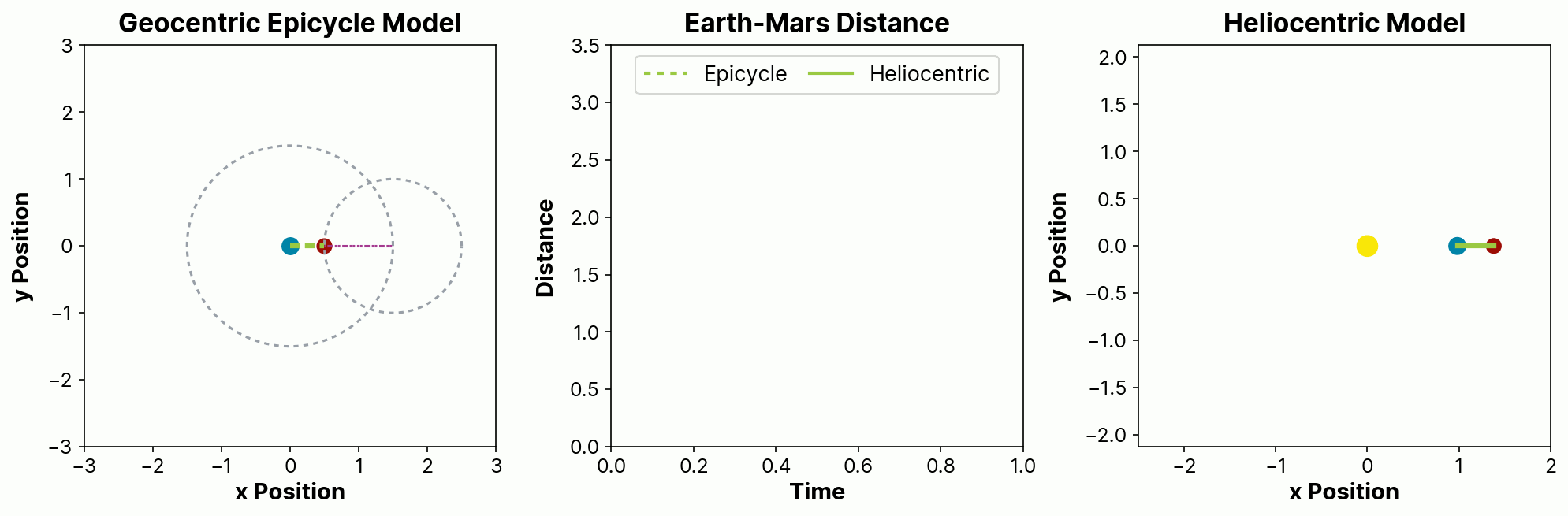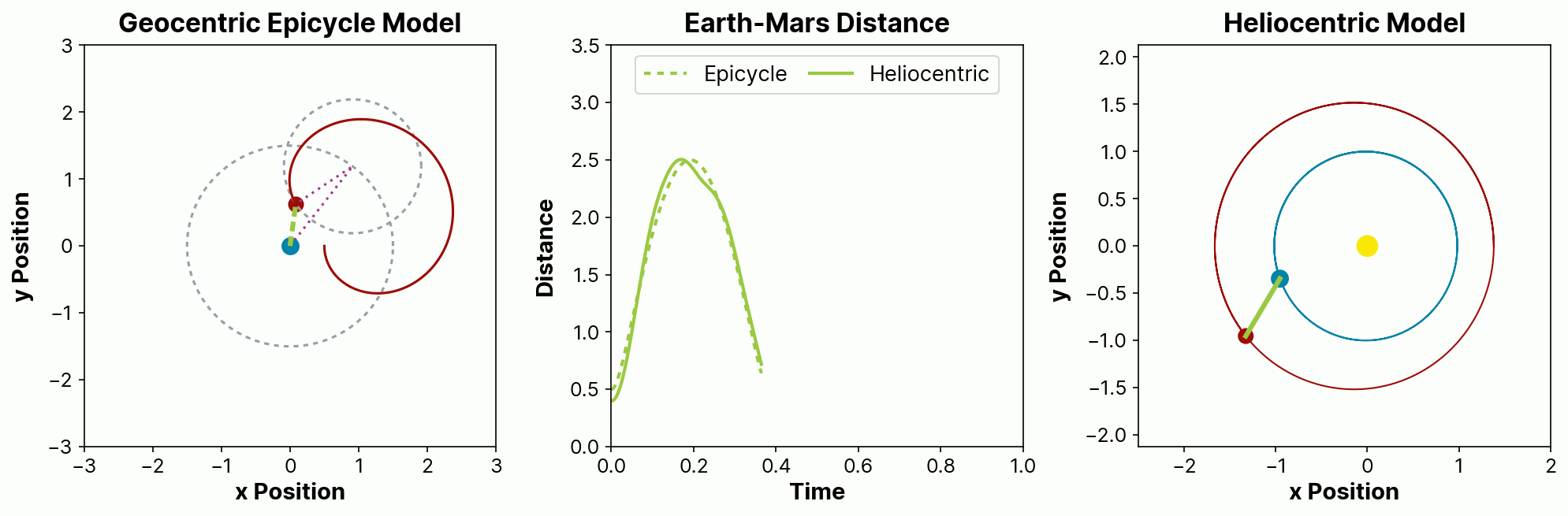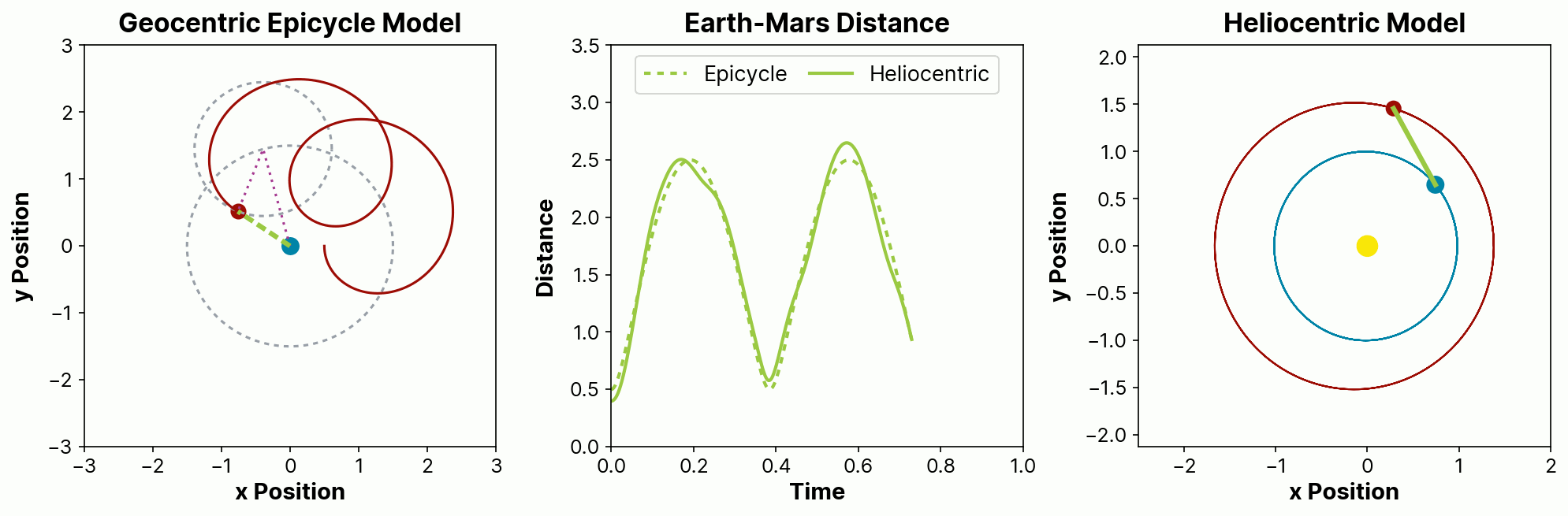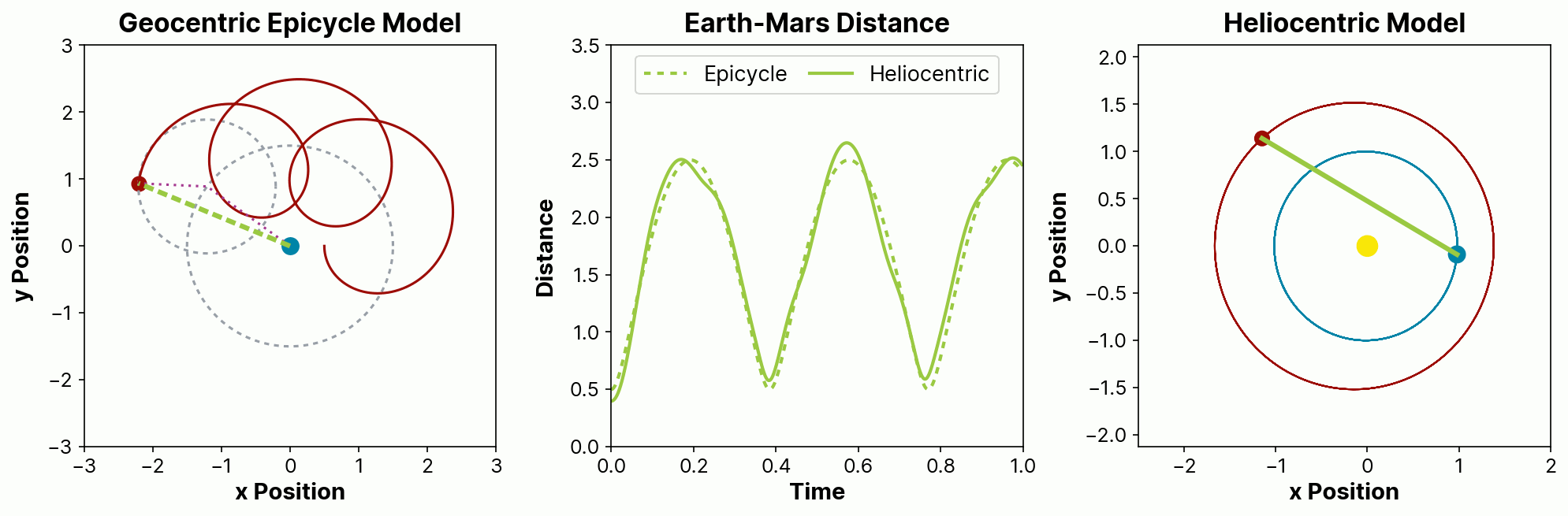
In this way, domain-directed approaches, including probabilistic programming techniques, specifically focus on a better understanding of the processes that lead to the creation of the observed data. This intrinsically causal approach allows us not only to ask both direct and counterfactual questions, but also to challenge our own assumptions. A causal model offers an opportunity to answer not just what might happen in the future, but why it would do so.
This especially comes in handy when we are entering a new domain we don’t yet understand in depth. Even though it requires more effort to establish a domain-driven model than an algorithmic one, the domain-driven model provides a foundation of understanding that can be extremely helpful as we develop our analysis. For example, as our understanding improves, we are better informed about which assumptions our prediction algorithms can safely make and which assumptions are inconsistent with our understanding of the world.
Machine Learning Models Can Provide Substandard Performance Due to the Absence of Domain Knowledge
Unfortunately, modern data science workflows often incorporate few or no elements of domain-directed understanding. Ultimately, when data scientists go about their work, we are conducting statistical analysis and modeling of some sort, whether simple or complex. In many cases, this work begins with generating simple summary statistics and creating preliminary visualizations of the data. Then, when we are still only just beginning to understand the domain, we often stop exploring the underlying system, leap into generating algorithmic model predictions, and tune the model so that our evaluation metrics are optimized.
In part, this leap is driven by the high-quality off-the-shelf prediction algorithms available in popular libraries like scikit-learn and prophet. With these kinds of solutions, we might obtain an algorithmic model with relatively good predictive power, but it’s reasonably likely that we will observe substandard performance and have little understanding of why. Further, it will be difficult for us to improve the model without modifying or expanding the dataset. In these situations, the only way to overcome the limitations of algorithmic approaches may be to switch to a domain-directed modeling paradigm, with the choice between deterministic and probabilistic methods being made based on the details of the system under study.
The Need for Better Uncertainty and Model Quality Estimates
While all data modeling approaches can be adapted to offer an uncertainty estimate along with their predicted outputs, many off-the-shelf solutions do little better than a mean estimate and some uncertainty bounds on that mean estimate. In many domains, that can lead to very deceptive results.
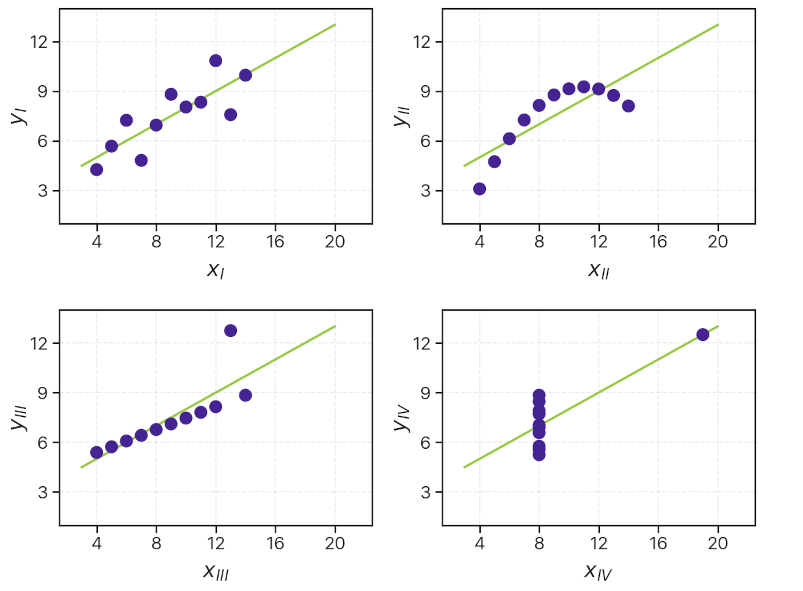
As one simple demonstration, the figure below shows Anscombe's quartet, a set of very different datasets that all yield identical x and y summary statistics (mean, variance, etc.) and linear fit parameters (slope, intercept, and correlation/R-squared value). While it’s easy to see that a linear fit with uniform error is a suitable model for only one of these four two-dimensional datasets, with high-dimensional data it is extremely difficult to visualize the quality of fit of an algorithmic model.
Without underlying domain-driven guidance as to a good shape for our model, we can’t easily trust whether the uncertainty and quality of fit parameters we derive from our summary statistics are large or small.
This principle was taken to an extreme with the Datasaurus Dozen dataset, where strikingly different visual patterns of data are shown to have nearly identical one-dimensional mean and standard deviation values, as well as identical correlation coefficients. Again, without an underlying domain-driven model telling us whether we expect star-shaped or dinosaur-shaped data, we really can’t tell whether the uncertainty and quality of fit represented by these summary statistics are large or small.
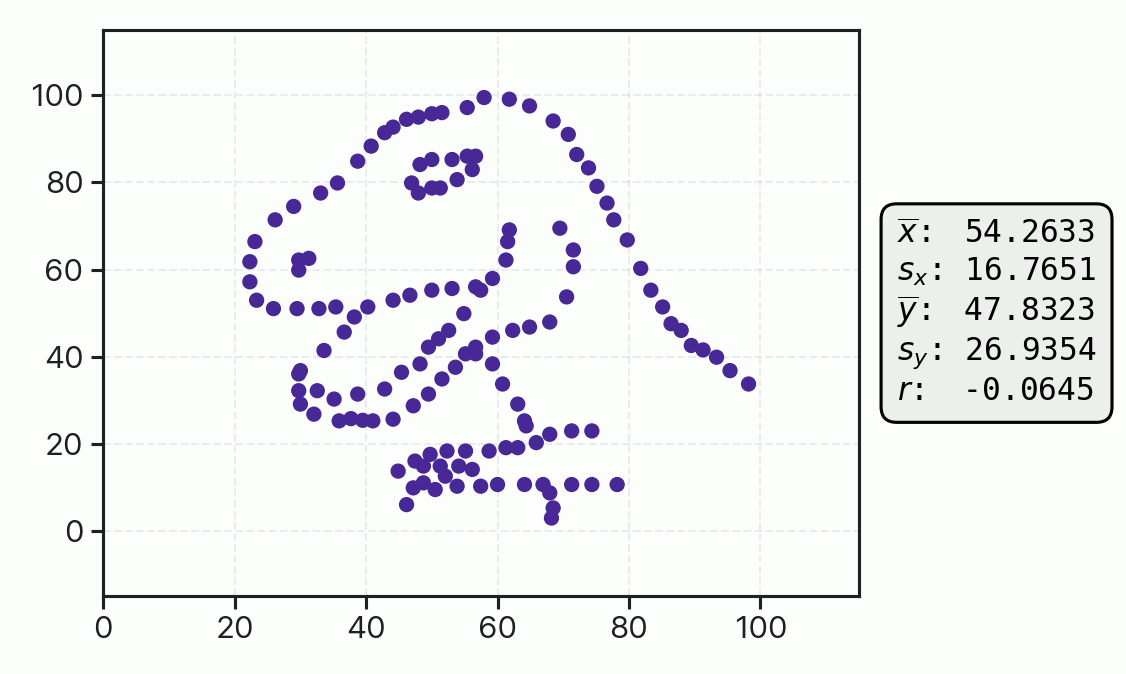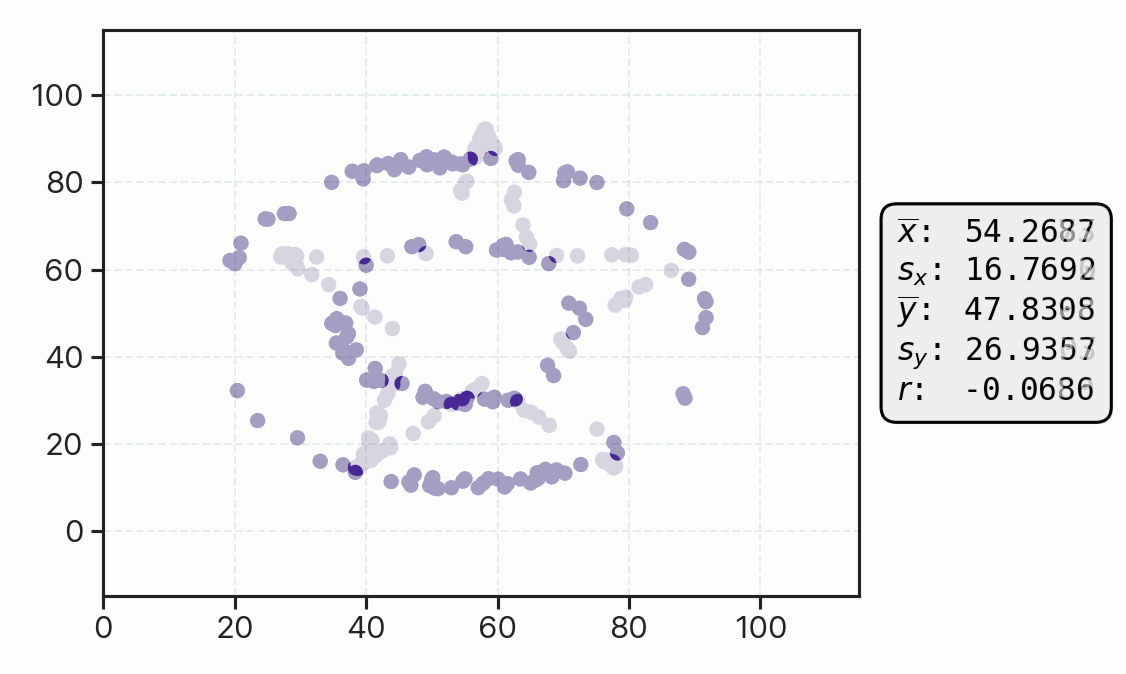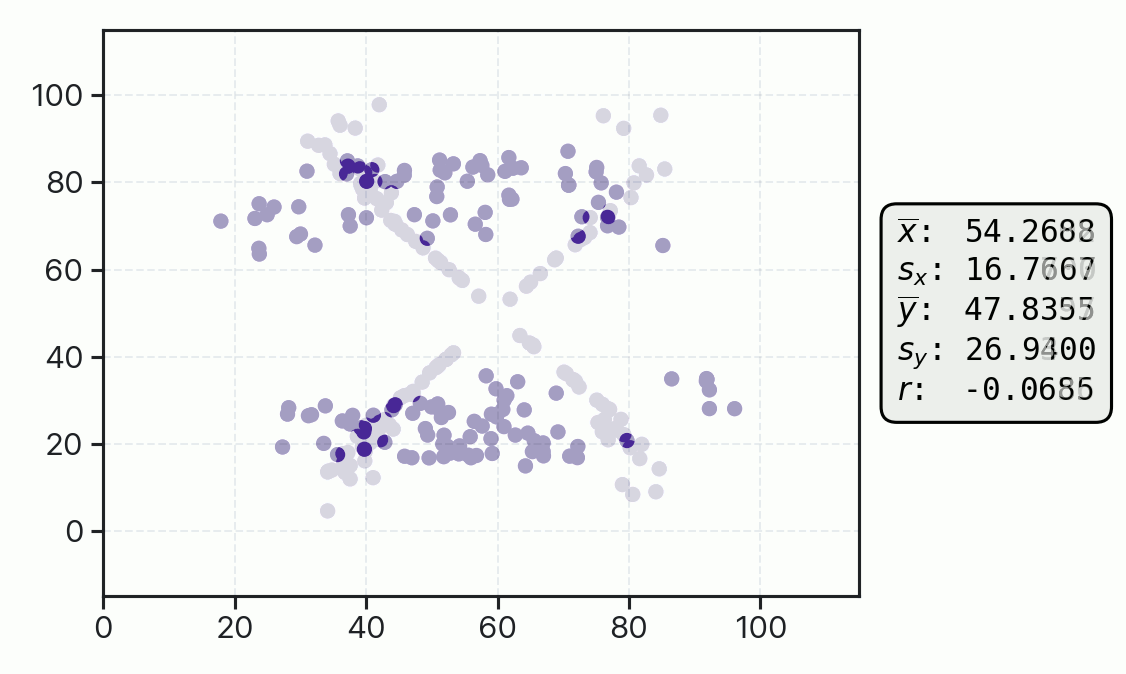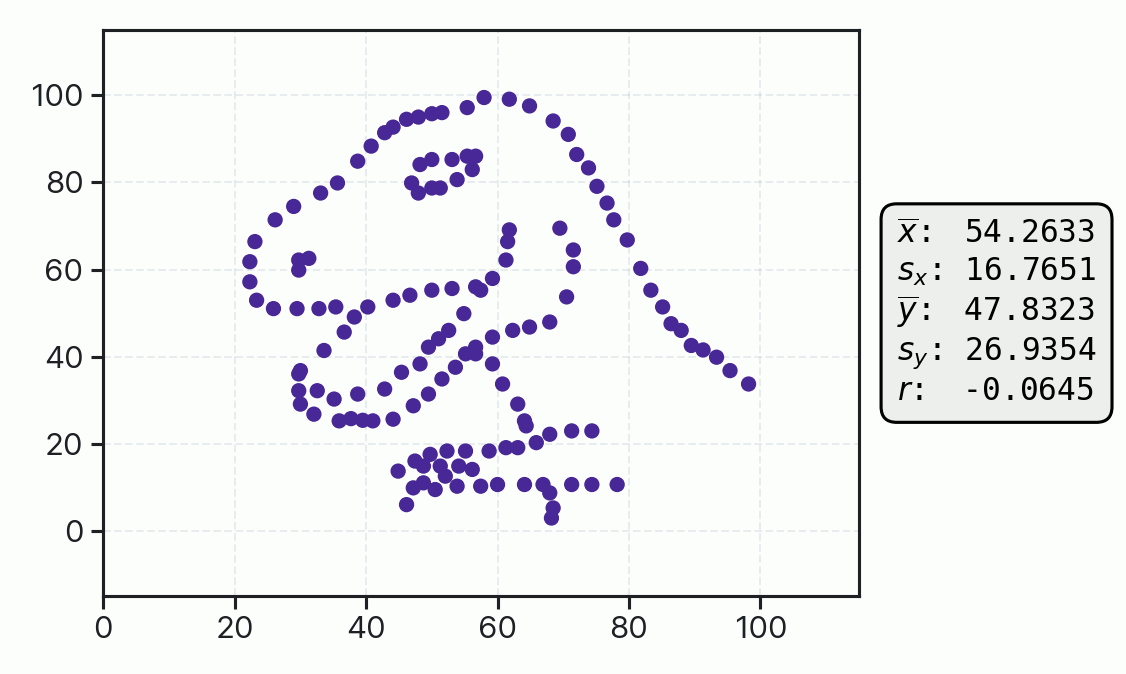
The above examples demonstrate how we are best served during data analysis by looking at our data directly with the guidance of a specific model, rather than just at its summary statistics. Similarly, we are best served during inspection of the inferences and predictions of our models if we bring to bear well established and understood statistical models and analytical tools.
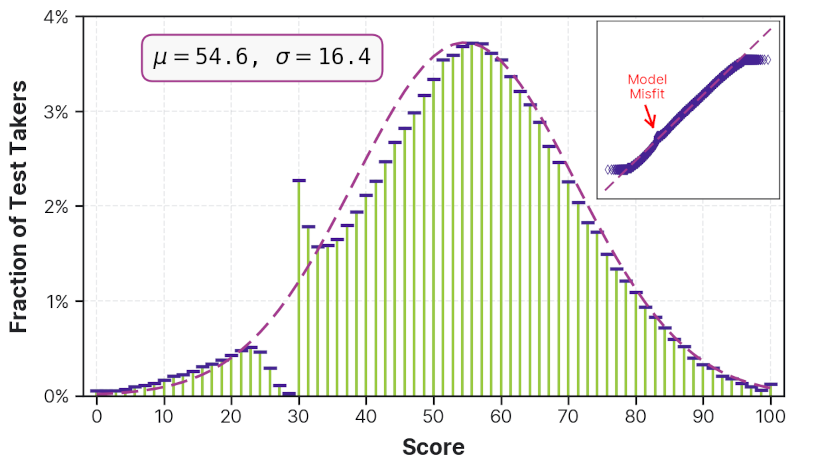
For example, the following histogram visualizes recent Matura exit-exam scores for a sample of high-school students in Poland. If we simply assume that exam performance should follow a normal distribution and only calculate a simple mean estimate with uncertainty bars, it would completely obfuscate the real story behind this dataset. First, the data clearly shows a deviation from a normal distribution, with an unexpectedly high number of students receiving scores at and just over the passing mark of 30, and an unexpectedly low number receiving scores just under 30. This deviation is visible in the probability plot of the dataset (inset), in the form of the “knot” in the data, as marked by the red arrow.
Further, the probability plot reveals that a normal distribution is not actually the correct distribution for this dataset, as shown by the deviation of both high- and low-end tails from the best-fit line. This is because the normal distribution assumes an unbounded domain for the data, whereas these data are bounded between 0 and 100, and a significant fraction of the data lies close to these bounds. A better choice for this bounded dataset might be something like a beta distribution, in combination with an additional model able to capture the discontinuity near a score of 30.
The use of domain-directed tools thus gives us access to more relevant models and their associated distributions, and the enhanced structure and insight they provide.
Probabilistic Programming Libraries As Domain-Directed Tools
These sorts of challenging statistical questions are usually better answered with a more bespoke model motivated by domain knowledge. For example, are we expecting our data to be linear versus curved? Star-shaped versus dinosaur-shaped? Binomially-distributed versus beta-distributed?
This is because there are typically relationships and interactions underlying the dataset that are hard to explicitly capture with standardized algorithmic machine learning methods. Probabilistic programming tools offer an approach to capture many of these complex relationships, by explicitly specifying the probabilistic model best suited for the domain at hand. They do this by providing a programmatic interface designed to mimic the notation statisticians have used for decades to describe their models.
For example, suppose you wanted to describe a probabilistic model of a linear relationship between X and Y. Statisticians might use the following notation:
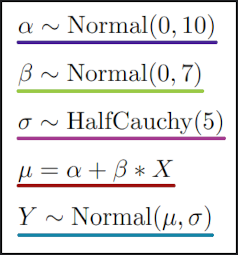
Here, the tilde (~) operator indicates that a variable is defined as being drawn from a distribution, rather than by a discrete equation. For example, in this system ɑ is drawn from a normal distribution with a mean of 0 and a standard deviation of 10, and σ is drawn from a half-Cauchy distribution (a Cauchy distribution only defined for positive values, since σ is the standard deviation of the distribution for Y and so cannot be negative) with a scale parameter of 5. Conversely, the intermediate quantity μ is defined as a direct combination of X and the two probabilistic quantities ɑ and β.
The following code sample is written to use functionality provided by PyTorch and Bean Machine, and describes the same relationships as the equations above:

The colored underlines in both of the figures are paired, to highlight the similarities between the definitions in code and the related mathematical representations. As you can see, the PyTorch/Bean Machine code expresses these statistical concepts in a form very similar to what we would write in standard mathematical notation, allowing us to easily craft a domain-directed model for our problem.
Just as there is no shortage of machine learning prediction libraries, there is no shortage of probabilistic programming frameworks we can use. Nearly all of these libraries have robust communities with deep expertise. Some popular choices at Quansight include Bean Machine, PyMC, Stan, and NumPyro and, in fact, multiple Quansight staff are contributors to both Bean Machine and PyMC. For more technical background on probabilistic programming, see the 2022 PyData London talk by Chris Fonnesbeck, which demonstrates the PyMC package, and either Bayesian Modeling and Computation in Python by Martin, Kumar & Lee or Probabilistic Programming & Bayesian Methods for Hackers by Cameron Davidson-Pilon, both of which are free and open-access.
Domain-Driven Modeling Outcomes Are Easier to Explain and Justify
Often algorithmic machine learning methods are optimized to produce the best predictions by adjusting the model to minimize prediction errors over the training dataset. But in the process of developing high-quality predictions in this fashion, they yield a trained model that is not very understandable and is challenging to interpret. Especially in settings where people carry legal or financial responsibility for the final decisions, predictions originating from poorly-understood models are hard to trust. Further, legislation is emerging in some jurisdictions requiring that companies be able to provide clear insight into software-determined financial and legal decisions, making some algorithmic models infeasible there.
In contrast, in a more domain-directed approach, every component of a model can be endowed with an interpretation that is meaningful to a domain expert. For example, in a time-series model, like the one below for the Mauna Loa monthly mean carbon dioxide data from 1970–2010 below, we can capture long-term trends (e.g., overall slope), medium-term trends (e.g., local deviation from the overall slope), and seasonal effects (e.g., cyclic annual or monthly variations). When such a model is fitted, each parameter is meaningful and something a stakeholder can consider when making decisions.
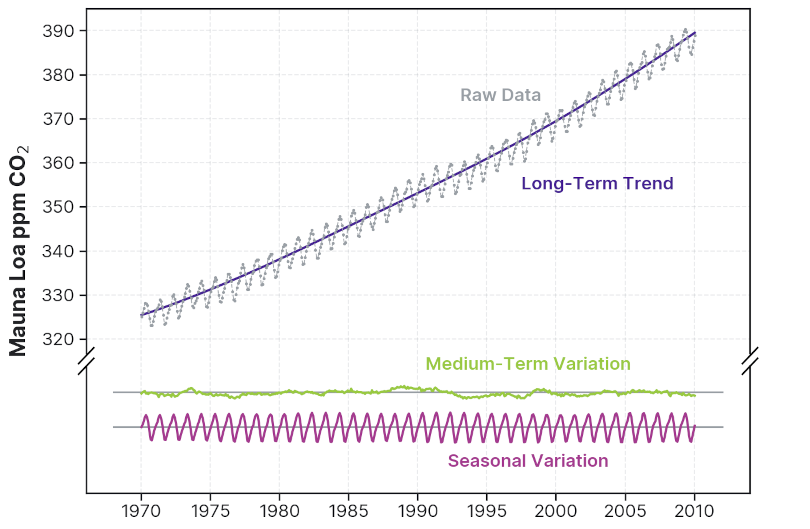
In addition, in some cases an underlying domain-driven model further allows us to perform causal inference from the dataset, as opposed to just identifying correlation, and potentially answer questions of significant practical value like: Did this marketing campaign cause this purchase? Did this drug treatment cause the patient to get better?
Domain-Directed Models Are More Robust to Noisy and/or Low-Volume Data
Algorithmic approaches really shine when you have relatively clean data, and a lot of it. But more often than not, the data is less than perfect. With enough data, modern machine learning and deep learning methods can often overcome these issues. But when you are just starting to understand your data and want to make predictions, you often won’t have enough data for robust algorithmic analysis. When there is not much data, finding good modeling assumptions can be the difference between successfully extracting the signal from the data and losing it to noise.
With the domain-directed approach, modeling possible sources of noise in your data will allow you to start making reasonable inferences early on about those sources. These inferences can even help guide subsequent data collection processes, which will help to improve the quality of future data. Even if you eventually move to a more algorithmic approach, you will have benefitted from insights obtained using the domain-directed approach.
In this way, domain-directed modeling can also be undertaken as an intermediary step between more basic data analysis and more prediction-focused machine learning methods, which you might use when you have more data available. The insights gained in those early modeling steps are essential to the development of future solutions.
Key Takeaways
There are many settings where domain-directed approach will shine, but both modeling approaches have their place with their assorted strengths and weaknesses. Here are a few takeaways to help you decide which approach will work best for you.
Strengths of Algorithmic Approaches
-
Standardized, with assumptions and shortcomings internalized by the community
-
Easier to deploy
-
Require less tweaking
-
Work well when assumptions in the data align with assumptions in the algorithm
-
Work better on large, clean datasets, with uniform confidence/importance across all data points
-
Unavoidable for datasets where no clear domain-directed model can be identified
Strengths of Domain-Directed Approaches
-
More interpretable
-
Easier to generate insights for decision makers
-
Better communicate uncertainty
-
Work better when datasets are small or medium sized (fit in memory on a single machine)
-
Easy to adapt to complex interconnected datasets
A domain-directed approach is not the best solution to every problem, but it is a very good technique for most problems. Even if a simple model can be confidently assumed for key parameters—for example, a normal, log-normal, exponential, or other distribution—you can gain the benefits of using a domain-directed modeling approach.
No matter what problem you’re trying to solve with your data, Quansight has expertise that can help. Whether you are just getting started or have established and deep expertise and need extra help to reach your goals faster, reach out to us for an initial consultation. We’ll be glad to help you make more of your data—contact us at connect@quansight.com.